159 lines
6.8 KiB
Markdown
159 lines
6.8 KiB
Markdown
---
|
|
title: 云计算 - Linux集群
|
|
date: 2023-05-18 12:56
|
|
tags: [云计算, 笔记]
|
|
categories: 笔记
|
|
thumbnail: "https://hexoimage.pages.dev/file/2369b0203a6961af7cd62.jpg"
|
|
---
|
|
|
|
## 概述
|
|
|
|
> - 群集基础
|
|
|
|
- [Linux群集概述](https://www.atdunbg.xyz/2023/05/18/cloud_linux_5/#jump0)
|
|
- pacemaker+ corosync+ pcS
|
|
- 演示:无共享存储的Web群集构建
|
|
- 演示:基于NFS共享存储的Web群集构建
|
|
- 使用Linux-IO构建iSCSI存储
|
|
- 演示:基于SAN共享存储的MySQL群集构建
|
|
- DRBD
|
|
- 演示:基于DRBD的MySQL群集构建
|
|
- GFS2
|
|
- 演示:基于DRBD+ GFS2的Active/Active的Web群集构建
|
|
|
|
## Linux群集概述
|
|
|
|
### 什么是群集?
|
|
|
|
> 集群是将-组计算机和存储设备组成在一起,作为一个整体系统来提供用户访问
|
|
> 集群中计算机共同来提供:
|
|
> \* 分担进程的负载
|
|
> \* 自动恢复集群中的一个或多个组件的失败
|
|
|
|
#### 群集术语
|
|
|
|
| 术语 | 描述 |
|
|
| -------------- | ------------------------------------------------------------ |
|
|
| 节点 | 参与群集的服务器 |
|
|
| 资源 | 托管在集群中设备或服务,被应用程序或最终用户直接或间接地访问 |
|
|
| 故障转移群集 | 一种高可用性集群类型。 在一一个时刻 ,资源只能单个服务器所拥有 |
|
|
| 负载平衡 | 负荷由由多个节点分担处理的集群类型 |
|
|
| 容错 | 集群的一个关键组件,能够在硬件或软件出现问题时还能继续运作 |
|
|
| 计划停机时间 | 由于更新或其他维护操作,应用程序不可用的时间 |
|
|
| 非计划停机时间 | 由于组件失败,关键应用程序不可用的时间 |
|
|
|
|
#### 群集类型
|
|
|
|
| 群集类型 | 描述 |
|
|
| ------------------- | -------------------------------------------------------- |
|
|
| 高可用(HA)群集 | 如果正在运行服务器遭遇失败,由其他的节点提供备份 |
|
|
| 负载平衡群集 | 将传入的网络请求分布到各个节点进行处理 |
|
|
| 高性能计算(HPC)群集 | 计算任务分布在多个节点 |
|
|
| 网格计算群集 | 独立的节点完成的被分派来任务或集群中其余部分分解的来工作 |
|
|
|
|
#### 群集实现
|
|
|
|
| 群集分类 | 描述 |
|
|
| ------------ | ------------------------------------------------------------ |
|
|
| 共享设备群集 | 在节点之间共享数据和其他资源 如果两个系统必须访问相同的数据,这些数据必须从磁盘读两次或从一个系统复制到另外一系统 |
|
|
| 无共享群集 | 无共享群集在每个节点有单独的资源 一个时刻仅有一个节点访问特定的资源 失败时,其他节点会取得对象的所有权 |
|
|
|
|
#### 群集优势
|
|
|
|
> - [可用性](https://www.atdunbg.xyz/2023/05/18/cloud_linux_5/#jump1)(Availability)
|
|
> - 集群增加的处于可操作状态的时间百分比
|
|
> 可伸缩性(Scalability)
|
|
> - 群集通过根据需要逐步增加资源,来满足所有处理能力或可用性要求
|
|
> [可管理性](https://www.atdunbg.xyz/2023/05/18/cloud_linux_5/#jump2)(Manageability)
|
|
> - 集群使配置、更新和添加等管理更加容易
|
|
|
|
### 什么是可用性?
|
|
|
|
> 通过以下方式提高系统的可用性百分比:
|
|
> \* 增加平均失效到达时间(MTTF mean time to failure)
|
|
> \* 减少平均恢复时间(MTTR mean time to recover)
|
|
|
|
| 可用性等级 | 每年宕机时间 |
|
|
| ------------- | ------------ |
|
|
| 2个9(99%) | 3.7天 |
|
|
| 3个9(99.9%) | 8.8小时 |
|
|
| 4个9(99.99%) | 53分钟 |
|
|
| 5个9(99.999%) | 5.3分钟 |
|
|
|
|
|
|
|
|
|
|
|
|
### 什么是可扩展性?
|
|
|
|
> 提高可扩展性的方式有:
|
|
|
|
- Scaling up
|
|
- 向一个节点添加更多的资源,如内存、CPU和磁盘
|
|
- Scaling out
|
|
- 添加更多的节点以分担负荷
|
|
- Consolidation
|
|
- 通过将多个服务器负载迁移到一个服务器或少量的高配置的计算机,让少量的服务器承担更多的负荷。
|
|
|
|
### 什么是集群的可管理性?
|
|
|
|
> - 群集通过以下方式来提高和可管理性:
|
|
|
|
- 灾难恢复
|
|
- 集群帮助应用程序的从灾难中进行恢复
|
|
- 更新管理
|
|
- 集群使应用程序、操作系统在升级更新时,仍然可用
|
|
|
|
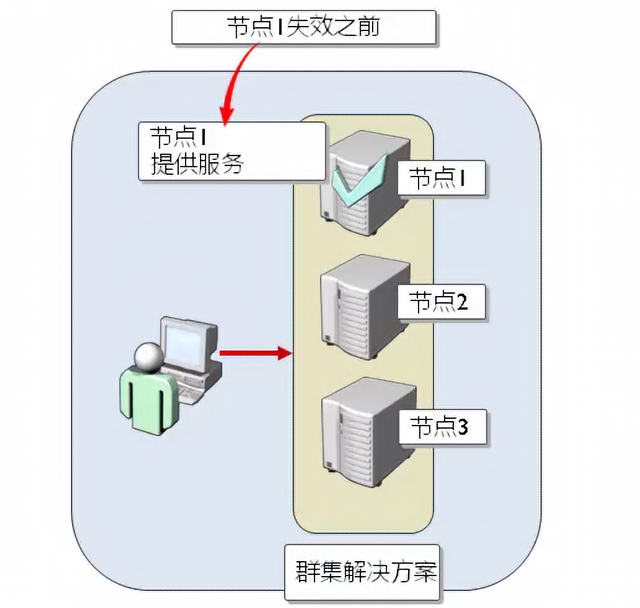
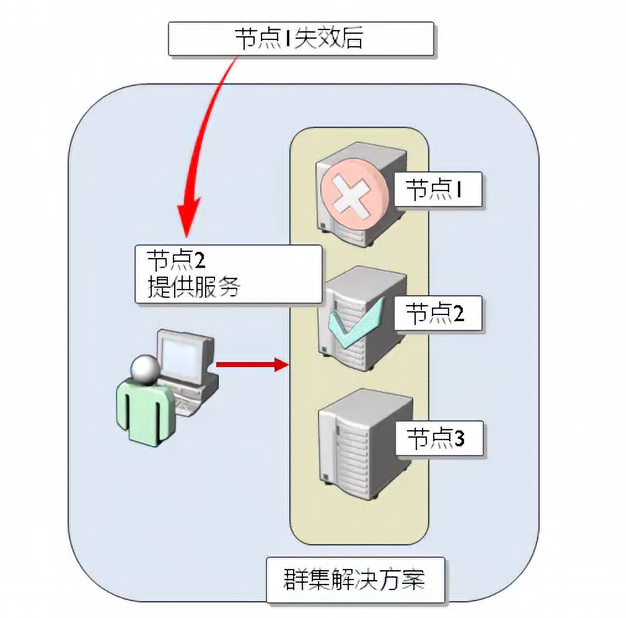
### 微软SQL Server故障转移群集工作原理
|
|
|
|
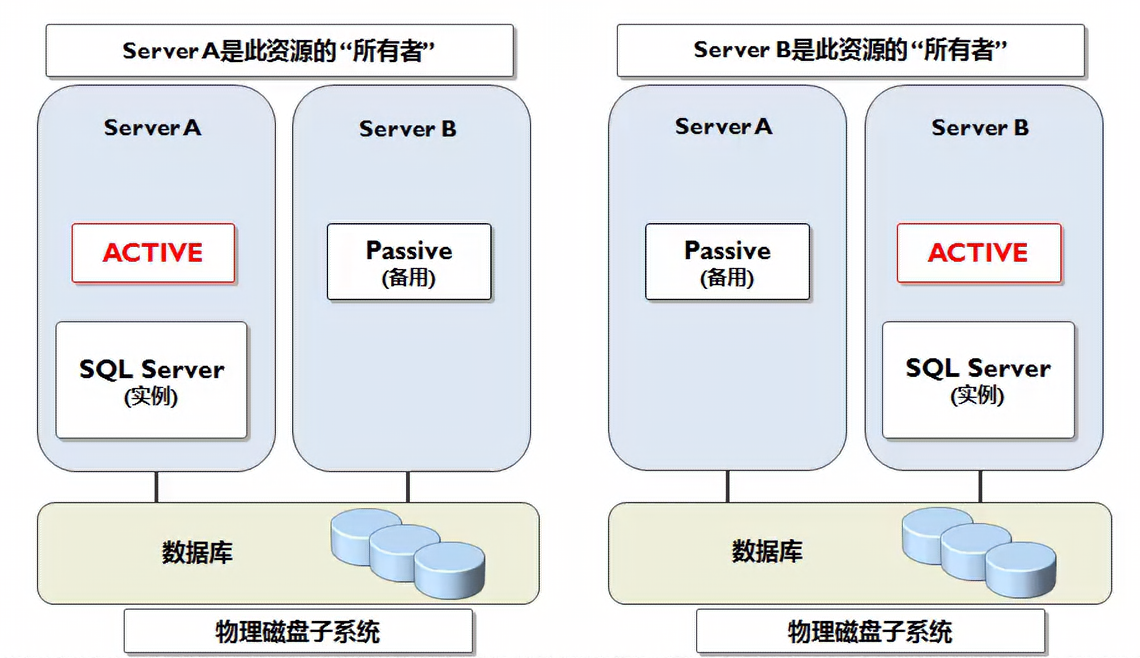
|
|
|
|
### 网络负载平衡( NLB)群集
|
|
|
|
> - 为网络服务提供可扩展性
|
|
> - 增强接收TCP和UDP流量的网络相关应用程序的可用性
|
|
> - 包含所有活动节点
|
|
> - 运行需要实现负荷平衡的基于IP的应用程序或服务副本,在每个节点保存所需的数据
|
|
|
|
### 什么是群集化的服务和资源?
|
|
|
|
> - 群集化的服务
|
|
> - 安装在故障转移群集以实现高可用的服务或应用程序
|
|
> - 在一个活动节点上,也可被移动到其它节点
|
|
> - 资源
|
|
> - 组成群集化服务的组件
|
|
> - 在一个时间,只能运行在一个节点之 上
|
|
> - 当一个节点失效时,可以被移动到别个一个节点
|
|
> - 包含的组件有共享磁盘,主机名和IP地址等
|
|
|
|
### 故障转移群集和网络
|
|
|
|
> - 故障转移群集使用以下网络:
|
|
> - 公共网络:用于客户与群集服务之间的通信
|
|
> - 私有网络:用于节点之间的通信
|
|
> - 存储网络:与外部存储系统通信
|
|
|
|
- 一个网络可同时支持客户与节点间通信
|
|
- 推荐使用多网以提供增强的性能和冗余
|
|
|
|
### 什么是仲裁(Quorum)?
|
|
|
|
> 在故障转移集群,仲裁定义足够的可用集群成员提供服务
|
|
>
|
|
> - 仲裁(Quorum):
|
|
> - 基于投票(vote)的
|
|
> - 根据不同仲裁模式,可使用节点,文件共享或共享磁盘用来投票
|
|
> - 当有足够的票数时,允许故障转移群集保持在线
|
|
|
|
- 合法:
|
|
- total nodes < 2 * active_ nodes
|
|
|
|
### 微软群集仲裁模式类型
|
|
|
|
| 仲裁模式 | 描述 |
|
|
| ---------------------- | ------------------------------------------------------------ |
|
|
| 节点多数模式 | 仅有群集中的节点有vote 当超过半数的节点在线时,才满足Quorum要求 |
|
|
| 节点和磁盘多数模式 | 群集中的节点和见证(witness)磁盘有vote 当超过半数的vote在线时,才满足Quorum要求 |
|
|
| 节点和文件共享多数模式 | 群集中的节点和见证(witness)文件共享有vote 当超过半数的vote在线时,才满足Quorum要求 |
|
|
| 非多数:仅磁盘模式 | 仅quorum共享磁盘有vote 当共享磁盘在线时,才满足Quorum要求 |
|